コンピュータとインターネットの発展により、われわれは以前には考えられなかったような多様かつ大量の情報を容易に共有・活用できるようになっており、このことが社会や暮らしを大きく変えています。このような環境を実現する基盤技術となっているのが「様々な情報を収集・分析・抽出する技術」と「そこから自在に検索する技術」です。これらの技術をさらに発展させ、世界中のあらゆる情報を有効に共有・活用できる情報環境を実現することを目標に研究を行っています。
1.Web情報を利用した社会情報分析
現在のWeb上には様々な情報が集積されており、実社会に関する様々な情報をも収集できるようになっています。そのため、Webは社会のセンサーであるとも言われます。しかし、Web上の情報には偏りがあり、社会の正確な姿を知るにはこの偏りを補正する技術が必須です。そのような補正を行う技術を開発することを目的に研究を行っています。
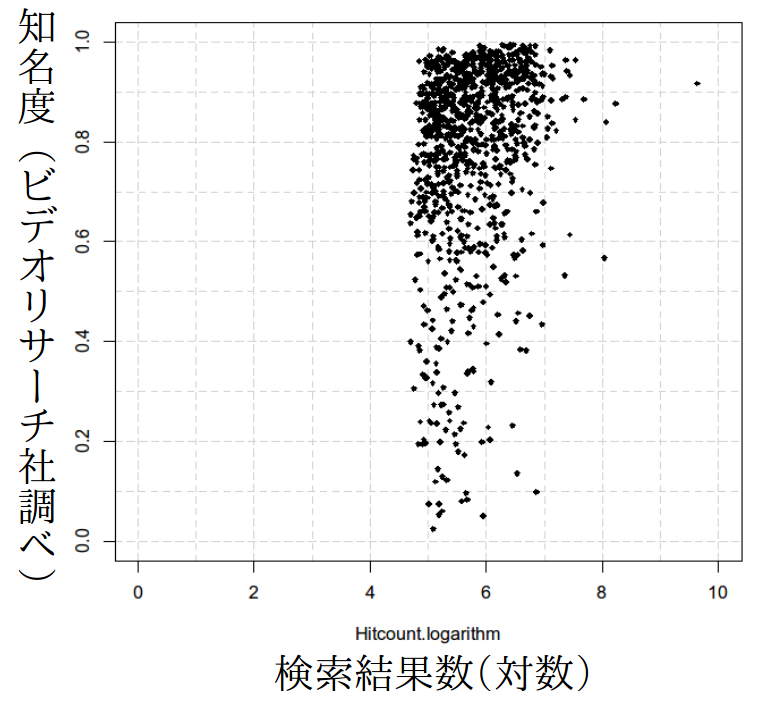
| 有名人の知名度とWeb検索数の関係 | ||
 |
 |
|
| 有名人1000人の知名度(縦軸,ビデオリサーチ社調べ)とWeb検索結果数(横軸,対数)。Web上の情報には偏りがあり、検索結果数から単純には知名度は推定できない。 | 社会の正確な姿を推定するにはデータから偏りを取り除く技術が必要。 |
2.ソーシャルネットワーク分析
実世界の手掛かりとなるWeb上の重要な情報源の一つに、ソーシャルネットワークがあります。ソーシャルネットワークのデータは個人レベルのミクロな情報やリアルタイム性の高い情報の情報源として特に有用です。この情報源から様々な情報を抽出する技術を開発しています。
これまでの研究の例:
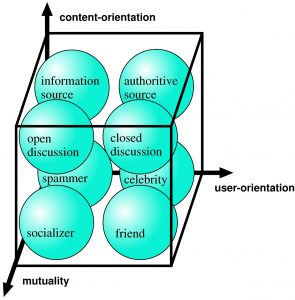
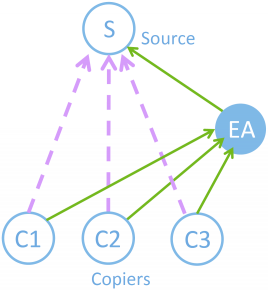
| Twitterのフォロー関係の分類 [Tanaka, Takemura, Tajima, ACM HT2014] | Twitter上のearly adopterの発見 [Imamori, Tajima, ACM CIKM2016] | |
 |
 |
|
| Twitterのフォロー関係の三つの分類軸(content-orientation, user-orientation, mutuality)を用いた分類。例えば、有名人へのフォローの多くは、特定のトピックのみを目的とするcontent-orientationは低く、そのユーザでなければ意味が無いというuser-orientationは高く,相互コミュニケーションを目的とする度合いmutalityは低いフォローの例となっています。 | Twitter上には、「early adopter (EA)」と呼ばれる、新しい有用な情報源をいち早く発見してフォローするユーザ達がいます。そのようなearly adopterを発見できれば様々な応用に利用できます。例えば、「現在はフォロワー数が少ない新規ユーザでも、early adopterにフォローされているものは今後人気が出る可能性が高い」などのように、新規ユーザの今後の人気予測に使えるでしょう。そのようなearly adopterは、自身も多くのフォロワーを持ち、early adopter がある情報源 S をフォローすると多くのフォロワーが真似をして S をフォローするので、上図のような三角形が多数できます.そこで、この三角形を数えることで、early adopterを発見する手法を開発しました。 |
3.クラウドソーシング
人工知能が人間から仕事を奪うということがしばしば語られますが、理想は人間と人工知能の最適な役割分担を実現することでしょう。そのような世界を目指す研究の一環として、人間と人工知能の協働作業、その中でも特に「クラウドソーシング」と「機械学習」の最適な役割分担を実現するための研究を行っています。この研究は、科学技術振興(JST)CRESTプログラムの中で「CyborgCrowdプロジェクト」として筑波大学,富山大学との共同研究で行っています.
| CyborgCrowdプロジェクトのロゴ |
| CyborgCrowdプロジェクトのロゴ。赤丸は人間、黒丸はコンピュータを表し、両者が最適な役割分担をしている様子を表しています。 |
これまでの研究の例:
| 他クラス分類タスクの階層的分類による最適な役割分担 [Duan, Tajima, WWW Conf. 2019] |
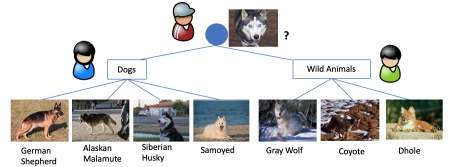 |
| 7種類のイヌ科の野生動物や犬種の写真を分類するタスクを考えます。作業者の中に犬の犬種に詳しい犬愛好家もいれば,野生動物に詳しい専門家もいるのであれば,全員が七つのクラスへの分類を行うよりも、上の図のような三つのサブタスクからなる階層的分類の形に変換し、まず、写真を犬と野生動物に分類し、犬に分類された写真は犬愛好家にさらに詳しく分類してもらい、野生動物に分類された写真は野生動物専門家に分類してもらう方が、分類精度が上がることが期待できます。また、最初の犬と野生動物へのおおまかな分類は人工知能で十分可能なのであれば、その部分を人工知能が役割分担することも考えられます。しかし、他クラス分類タスクが与えられた時に、どのような分類階層を用いたタスクで実行するのが最適かは自明ではないため、最適な分類階層を発見する技術を開発しました。 |
4.情報アクセスインタフェース
大量情報の処理では、かつては計算機の処理を早くすることが最重要でしたが、現在では、計算機は十分早いが人間がその出力を閲覧するところが律速段階という状況も増えています。そこで、人間が大量の情報を効率的に閲覧するためのユーザインタフェースの研究を行っています.
これまでの研究の例:
| Webページのサムネイル表示を用いるタブブラウザ [Liu, Tajima, ACM IUI2010] |
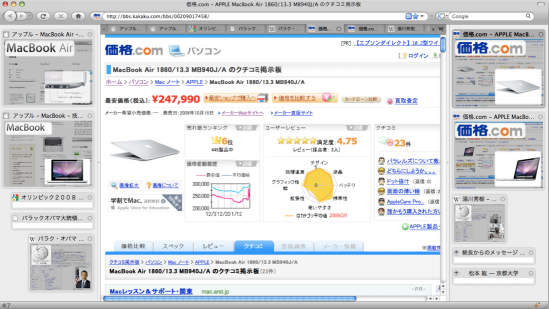 |
| ブラウザにおいて多数のWebページを開く際に、タブによる表示ではどのタブがどのページかわからなくなるので、Webページのサムネイルを表示するようにしたブラウザ。サムネイル表示でも、多数のサムネイルを表示して一つ一つのサムネイルが小さくなると、同一サイトのよく似たページなどの区別がつかなくなる。そこで、サムネイル内で、そのページのサイトのロゴと、そのページで最も重要と思われる画像を拡大して強調表示している。この二つを表示すれば、ほとんどのWebページは区別ができる。 |
5.情報検索
Web検索と言えば、キーワードを入れると、それに関連するWebページのスニペットがリストされるというスタイルが確立されていますが、今の姿で十分かつ常に最適とは言い切れません。日々、大量の人間が膨大な時間を情報検索に費やしており、この作業効率の向上は社会的に重要な課題です。